Author: mtutty
Securing GForge on Apache httpd Server

Secure connections are integral to keeping your important information safe, on the Internet or your private company network. For years itâs been fairly simple â turn on SSL, buy a certificate and let the browsers ensure that your data stays private. Unfortunately, itâs no longer that simple.
Over the last 15 years, computing power, virtual servers and good, old-fashioned software bugs have all conspired to make much of the encryption plumbing from the last 15 years obsolete. In fact, itâs very likely that if youâre running Apache httpd and mod_ssl, youâre allowing protocols and ciphers that expose your server (and your data) to needless risk of compromise.
Note: If youâre a customer, and GForge Group manages your server, these security updates are already in place. Get in touch if you have any other questions.
Check Yourself
Itâs actually pretty easy to test your system, and it can be done in production, without affecting your current users.
For servers that are on the Internet, you can use an online scanner. Hereâs SSLLabs, from Qualys:
Enter your siteâs URL and click Submit. After a minute or two, youâll get output like this:
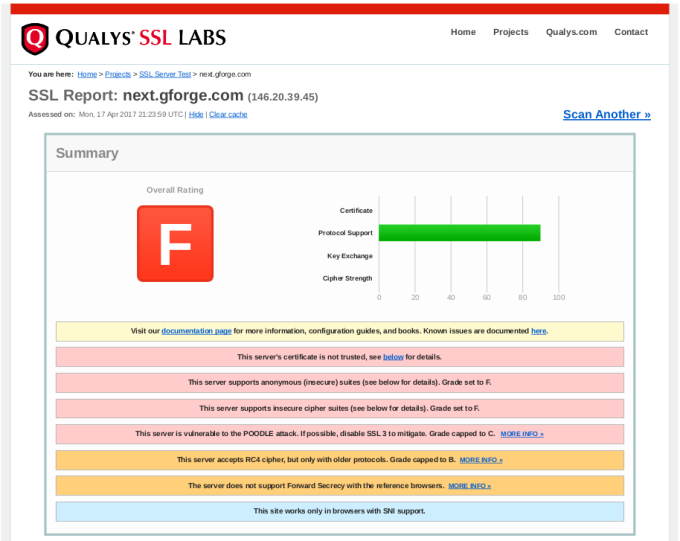
In the report details, you will find explanations of anything marked as a problem from your server, including how to close security holes that were found.
If your server isnât on the Internet (i.e., on your internal network), then youâll need to download and run scanning tools yourself. Here are some popular ones:
- TLS Observatory â An open-source scanner from Mozilla, written in Go. Youâll need the Go runtime to run this on your server or desktop, or you can use the Docker image. Performs scanning for both the SSL/TLS version and cipher suite(s) in use.
- Cipherscan â Another tool from Mozilla, written in Python.
Get With The Times
After running your scans, youâll need to decide what changes (if any) to make to your SSL configuration. Itâs important to understand that choosing the most up-to-date settings will leave out some older clients. Fortunately, Mozilla also has a great online tool to help you balance security with compatibility.

Give this tool your current version of Apache httpd and OpenSSL, and youâll get various choices for maximum security versus maximum compatibility.
Our Recommended Configuration
In the end, we went with the Modern configuration, but added the AES256-SHA256 cipher back to the list. This allows only TLS 1.2 (the most secure), but adding that one cipher back keeps compatibility with older non-browser clients like curl, so that existing SVN and git over HTTPS are not broken.
Hereâs the configuration snippet we recommend for GForge servers:
<VirtualHost *:443>
...
SSLEngine on
SSLCertificateFile /path/to/signed_certificate_followed_by_intermediate_certs
SSLCertificateKeyFile /path/to/private/key
# Uncomment the following directive when using client certificate authentication
#SSLCACertificateFile /path/to/ca_certs_for_client_authentication
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
...
</VirtualHost>
# modern configuration, tweak to your needs
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1
SSLCipherSuite AES256-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256
SSLHonorCipherOrder on
SSLCompression off
SSLSessionTickets off
# OCSP Stapling, only in httpd 2.3.3 and later
SSLUseStapling on
SSLStaplingResponderTimeout 5
SSLStaplingReturnResponderErrors off
SSLStaplingCache shmcb:/var/run/ocsp(128000)
Signs That Youâve Outgrown Github, Part 3:Â Merges
This is part 3 in a series about the limitations of Github, and how they might be holding your team back from its full potential. If you want to go back and catch up, hereâs Part 1 and Part 2.
Go ahead, Iâll wait right here.
Done Okay, letâs move on.
Todayâs discussion is about getting code merged. Itâs one of the most fundamental things any software team has to do. If your team is anything like ours, itâs something you do many times every day. It might even be the kickoff for your Continuous Integration/Delivery process, as it is for us.

Getting things out quickly is important, but preventing outages from bad code is even more important. You probably want an easy way to review and even test code that doesnât distract too much from the work youâre already doing.
Once again, Github has a wonderful system for promoting code from one repository or branch to another â the Pull Request (PR herein). In particular, the PR is great for open-source projects where people might want to contribute, even if theyâre not members of the main project. The proposed contributions can be examined by the main project member(s) and be pulled in only if theyâre helpful.

But like many other Github features, you may find the PR process to be mis-aligned to your needs, in a way that creates a little extra delay and a bit of confusion every time you use it.
Pull Requests 101
For those who havenât tried one yet, a pull request (PR) is a special kind of task, asking someone to merge a set of changes (commits) from one place to another. In more general terms, you can think of it as promoting a chunk of work from one level to another â such as from a development branch to test and then to production, or from a hotfix branch to long-term-support.

Because itâs a request, it doesnât involve any access to the project repository from any non-members. The project team can review the proposed changes and take them, ask for revisions, or ignore them. Itâs a great model for open-source or otherwise loosely-coupled groups to share ideas and improvements.
Keep It In One Place
But that flexibility comes at a cost. Pull Requests are opened and managed separately from individual tasks, so youâre basically creating another task to review each taskâs work. The open or closed status of each task can be independent of the status of the related PR. Additionally, thereâs nothing stopping someone from submitting changes for multiple tasks in one PR, which can be confusing and difficult to review.
For software teams that arenât open-source, this loose coupling actually creates more process, more overhead, and time thinking that could be spent doing instead.
Ask yourself â wouldnât it be a lot easier to merge the code as an integral part of the task itself
Singularity Of Purpose
Letâs start with an assumption â that in order to change your code, there should be a defined reason for doing so.
Youâre writing code because something needs to be added or fixed. Thereâs a use case. A story. A bug. A feature. A customer who wants something. Thereâs a reason to change what you already have.
You probably also want to do two things with your tasks:
- You want to create a plan ahead of time, for which things will be done, by whom, in what order.
- You want to keep track of progress as things move along.
Once you start depending on tasks for planning and tracking, you can begin to improve your overall process, reducing the number of steps and the distance between idea and working code. As you do, separate PRs may start to lose their appeal. Asking developers to open a separate kind of ticket to get code merged is a hassle. Allowing them to put multiple bug fixes into one merge is asking for confusion and mistakes.
If youâre delivering code using a well-defined workflow, PRs can actually cause problems:
- Audit trail â Itâs difficult (or impossible) to know later which code changes went with which task.
- Larger merges â the code review itself becomes much more complicated, since there are more commits, more changes files.
- All or nothing â If you like the changes for task #1, and for task #2, but there are problems with the tests for task #3, the whole PR is sent back for rework. This means youâre likely sitting on changes for longer.
- More conflicts â Pretty simple math: (Larger merges) + (All or nothing) = More conflicts.
Since thereâs no way in Github to limit the content of a PR, thereâs no good way to prevent this kind of behavior. Creating a PR for every single bug becomes a tedious time-sink that doesnât add value to your day.
Now, you might argue that a Github PR can act as the task itself, and it does â but not really. PRs are only retrospective, meaning that you create one after (or while) doing the work. If you donât create tasks before doing the work, then youâll never have any way of planning or tracking progress.
Simplify, Simplify
For most teams, the overlap between tasks and PRs is additional work that doesnât generate any value. What you really need is a way to automatically detect code changes, review those changes and then promote them to dev, test and production, all as part of the task.
This kind of integration means that you can go back to the task later, understand the intent of the change, and also see the code changes that went with it. Your task tracking becomes a source of institutional memory, so that people can move in and out of the team, or across different features without making old mistakes over and over again.
If your tools are preventing you from improving your process, maybe itâs time to improve your tools.
Come try GForge Next for simple, comprehensive and elegant collaboration.
Signs That Youâve Outgrown Github, Part 2: Task Management
In my last post, I introduced a set of features (and failings) that might have you wondering if Github can grow with your team. In this post, Iâm talking about tasks, workflow and keeping things moving.
Githubâs Workflow Is Simple And Cool
When youâre starting out, Githubâs approach is really helpful. You can create a task with just a summary sentence. If you want, you can add a more detailed description and some labels.
Tasks are open or theyâre closed, and you can close a task with a commit. From a developerâs perspective, itâs wonderful to grab a task and write some code, then update the task without having to visit the website. You get to stay in your IDE, your command-line â whatever tools youâre using to do the work.

The Real World Gets Complicated
These features work very well for teams that are just starting out, and for projects that may have somewhat disconnected participants (e.g., open-source projects). But as your team begins to deal with marketing, sales, customers, or even other dev teams, you may rub up against some important limitations.
Thereâs more to life(cycle) than Open and Closed
Very often, there are other pieces to your workflow than just coding. There could be planning, design, code review, testing, deployment, and other activities. Itâs pretty common to reflect some of that workflow in the status, so that everyone can tell where a task is and what needs to be done next, without having to re-read then entire history.

Closing a task just because youâve committed some code assumes that everything else will go right. Usually, committing code is the beginning of the process, not the end.
Not everything fits in the same box
Not everything is a task to be done in the code. Sometimes, you want a place to flesh out a user story, or discuss the design for a specific page. Maybe you need to track servers, or which customers have which version of your product.

You might be able to jam these different kinds of information into a Github task, but it ends up being a bigger version of the labeling problem from my previous posting.
Whatâs going on
Github has some pretty decent release/milestone tools, and you can group tasks into a milestone to track overall completion. That project-level view can be great, but what about planning and tracking your current sprint Or planning and tracking your own day
Standups get a lot easier when you can automatically see what the team worked on recently, and when the team can identify what they plan to work on.
Whatâs really important
This is one that everyone runs up against pretty quickly. Putting a priority on each task allows the team to keep moving, by knowing which tasks to work next. Without prioritization, everyoneâs just guessing about what is most important.
Github has no way to prioritize tasks. Even if you use a label (to beat a dead horse), you wonât be able to sort them.
Plans get tangled up
Itâs pretty easy to enter and manage tasks in Github, and depending on your level of detail one task might be completely stand-alone from another. Almost inevitably, though, a task will be blocked, waiting for some other task to finish. Your new web page needs an API update from someone else. A customerâs support ticket might be waiting on a bug that someone is working on. Or a use case canât be complete until all three web pages are working together.

The ability to manage dependencies has been asked and discussed many times over the years, and Github just doesnât want to take on the complexity. It doesnât have to be a Gantt chart, but making sure that everyone knows when tasks are blocked (and when they become unblocked) is key to maintaining project momentum.
A More Realistic Approach
First off, donât expect Github to change. The simplicity of their task management is perfectly suited for many, MANY projects. Itâs easy to get started with, and is a great place for sharing open-source and personal projects.
But maybe your team has started to suffer from that simplicity, and youâre looking for something to fill in the gaps that Github leaves. You might even be tempted to try one of the dozens of âbolt-onâ tools that claim to integrate tightly with Github.
Instead, let me suggest that what you really need is something that was built from the ground up to start simple, grow to be comprehensive, and stay elegant. Something thatâs easy to use, but allows more complexity as you grow into it.
Here are a few more simple pieces of advice:
- Instead of shying away from adding different status values, be honest about the workflow you want and make the tool serve your needs.
- Consider that maybe you need a different set of fields for tracking use cases or UI designs, versus coding tasks, versus customer support.
- Donât settle for something thatâs too simplistic, or a patchwork of loosely-coupled tools, when working around their limitations will cost you time thatâs better spent on your actual mission.
If your tools are preventing you from improving your process, maybe itâs time to improve your tools.
Come back soon for another sign that you might have outgrown Github .
Come try GForge Next for simple, comprehensive and elegant collaboration.
Signs That You’ve Outgrown Github
Github is WONDERFUL. I have used it for a long time now, and itâs great. Itâs easy to get started, and especially for one-person projects, it really helps keep things organized.
But as you start to add team members, competing priorities, and overall complexity, something changes. In lots of little ways, Github starts to show that it just wasnât designed for long-haul software projects, with many team members and a non-trivial workflow.
Here are some of the things you might already be dealing with:
- Youâve created so many labels that youâve written a wiki page to tell everyone how to use them (and how NOT to use them!)
- Maybe you want to keep track of bugs and support tickets separately.
- Perhaps you donât think that developers should be able to close a ticket just by committing code.
- Maybe youâre tired of having to search in Google Docs, Basecamp, Slack and Github to find where you talked about that new feature.
- Could be that you need to manage the relationships between tasks that depend on or block each other.
Iâll do a blog post for each of these topics. This week, letâs start with the first one â labels.
Labels
Labels are quick and easy to use, offer a lot of flexibility and require virtually no setup or configuration overhead. The default labels in Github look something like this:
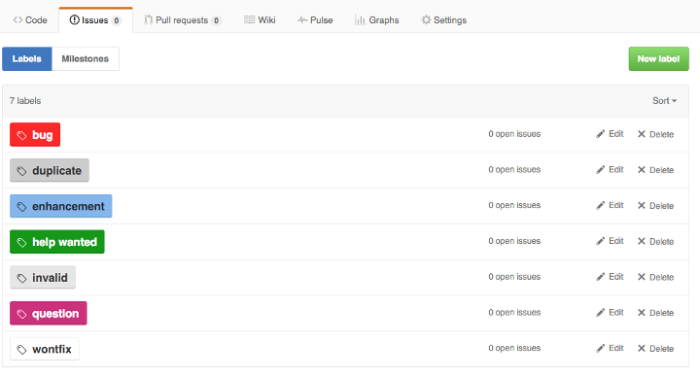
Those are probably fine for 98% of new Github projects. Over time, however, most teams will expand on the list of tags to include different values than the default list, and even different types of data. Adding categories for basics like type, priority, and status makes a lot of sense when youâre managing a backlog. But all of those new values expands the list beyond what you can keep straight in your head.
So, how can teams use complex label sets reliably One common convention is to use a prefix word to identify the group to which each label belongs (courtesy of Dave Lunny):


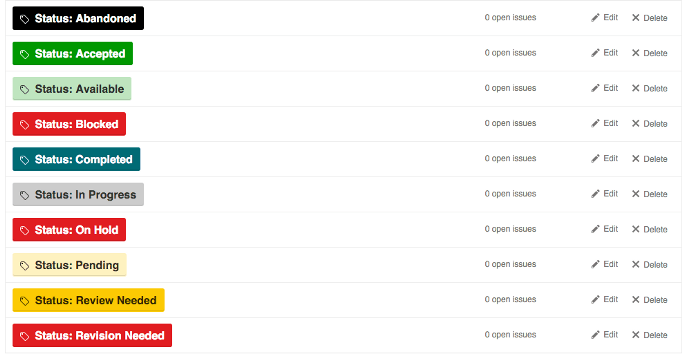
This approach has the benefit of including the type of label as part of the label text, so you wonât be confused between âStatus: Testâ, âEnvironment: Testâ, and âTask Type: Testâ. Visually, the various colors can be used to show differences in the specific values, like production vs non-production, or high priority vs lower priority.
The downside is that when viewed across label types, the different colors are confusing and even downright jarring. Instead of quick visual signals based on color, you actually have to read each label value. Itâs bad enough when looking at a single task, but when browsing a list of tasks, it can be a hot mess.
Another approach is to use similar colors for grouping. Hereâs an example (from robinpowered.com):
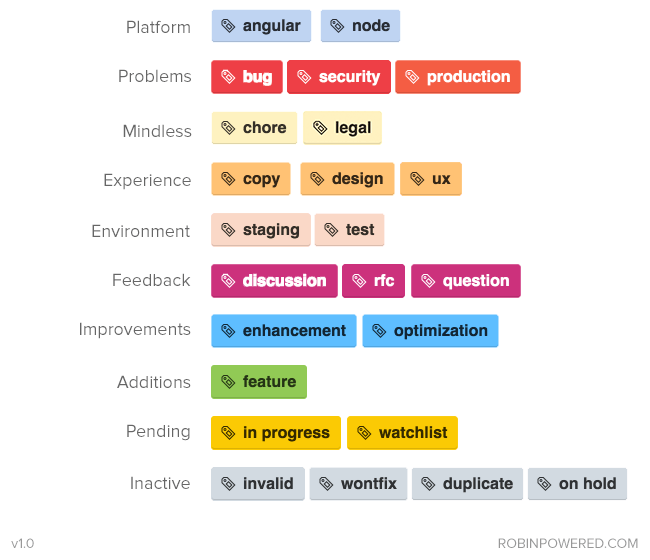
While itâs much easier on the eyes, you no longer have the label type included with the label value. Also, this particular set of labels combines and separates a lot of values in ways you wonât appreciate later â for example, why is the production label in âProblemsâ and not âEnvironmentâ Thereâs likely information on a wiki page somewhere, explaining that you donât choose anything from âEnvironmentâ when itâs a production issue, right
This next example isnât really an example at all, but a cautionary tale. Imagine walking into your first day with these guys:

This isnât someoneâs drug-addled fantasty project, either â itâs servo, a very active and popular project on Github.
Tools For Your Tools
In response to this widespread need, there are actually tools (like git-labelmaker) dedicated to helping Github users automate the creation and management of complex sets of labels, using different naming conventions, color schemes and labeling styles. Which is very cool â except that it seems like an awful lot of work to go through, doesnât it If someone has created a tool to help you use another tool, maybe itâs the wrong tool.
Tag/label functionality was never designed for complex values or workflow.
A Right-Sized Solution
Instead of a mashup of various labels, organized by a prefix word or a color scheme, consider this layout (with a few additions that are, IMO, obvious):

Separating these various concerns also allows you the flexibility to require some fields when a task is created, and wait for the right step in your workflow for others. Instead of manually enforcing your task management process, you can allow your tool to do it for you.
One last benefit â if youâre using separate fields instead of specific tag values, then changing the name of the field or the values over time wonât break old data. The new field name or value(s) will be reflected in older tasks automatically.
If your tools are preventing you from improving your process, maybe itâs time to improve your tools.
Come back soon for another sign that you might have outgrown Github â next time, weâll talk about Githubâs one-dimensional task tracking.
Come try GForge Next for simple, comprehensive and elegant collaboration.
How Many Project Tools Do You Really Need?

In my last post, I talked about some criteria for choosing between all-in-one or best-in-breed tools. Now, Iâll apply those criteria to our product space, and try to show why a unified team collaboration tool makes more sense than what you might be living with now.
So, letâs imagine that youâre looking to solve the following problem: How can we get everyone rowing in the same direction
By âeveryone,â we mean executives, product owner(s), designers, development staff, customer service, maybe even customers themselves.
And by ârowing,â weâre talking about all of the things it takes to get your product to the customer â things like planning, design, coding, marketing, testing and support.
The Accidental Integrator
The worst-case scenario is also the most common â each discipline area adopts whatever tools appeal to them.
NB: This is a simplified version of actual events from a previous job. The details have not been exaggerated, and the people involved were otherwise very capable, smart, and successful.
- The Product Owners all decide to use Trello, and thus force it on the development staff.
- The designers prefer Basecamp, where they can organize screenshots for the various user stories theyâre working on. This means that the Product Owner has to look there as well, and so do the developers, and possibly also the customers.
- The developers decide on Github, since itâs easy to start and Git is pretty awesome.
- Customer Support starts a wiki, so they can get all of their procedures and help scripts in one place.
- They already use FogBugz for tracking customer issues, and neither Trello nor Github has the features they need. This means that the Product Owner and developers have to look in FogBugz almost every day, as they respond to problems reported by customers.
- The executive staff needs all of the above to keep a handle on whatâs happening where. They also create and manage a couple of spreadsheets in Google Drive, to keep summary data for the various projects that are in process, and to prioritize upcoming work.
Hereâs what that set of tools ends up looking like:
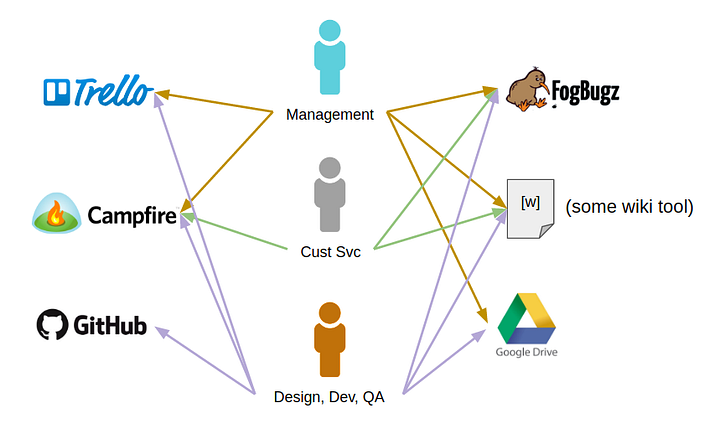
Of course, some of these tools can be tied together with vendor-supplied integrations, web hooks, or some simple scripting. Adding these integration points might make things more convenient for users, but it doesnât change the overall picture:
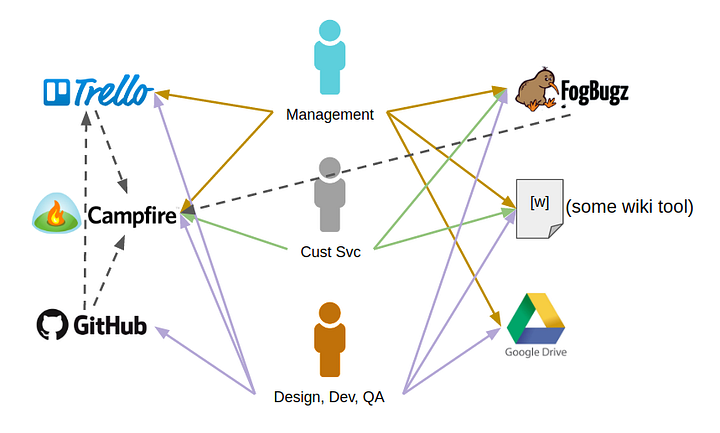
Inevitably, some amount of developer time each month (or week) will now be spent troubleshooting why x is no longer taking to y, and fixing it. People also regularly forget which password goes to which system, and need resets on a recurring basis. [Ed. This happens to me ALL THE TIME.]
Regardless of how good those integrations are, everyone still has to search across two or three or more tools to find what theyâre looking for.
Each tool you add is another silo of data and process, and more friction in the overall workflow.
A (Kinda) Integrated Solution
Many teams opt for the Atlassian/Microsoft/IBM approach â buying a set of tools from the same company, with the promise of tighter integration. Itâs sold as an all-in-one solution, in as much as youâre buying from one vendor. And for the most part, thatâs true â until itâs not.
Tool suites like these do a much better job at tying related data together â build status can show up in the related tasks, support tickets can reference wiki pages, chat can become your companyâs heartbeat. All of those capabilities help to decrease friction, distribute knowledge, and keep the entire organization plugged in to the right priorities.

But theyâre still separate tools. You still have to flip from one app to another to search, get the details, or make updates. Each tool is still deployed and managed in separate software versions, which (sometimes) fall out of compatibility with each other. And donât forget that youâre still going to pay licensing and maintenance for each tool. Even at a bundled rate, youâre probably getting soaked.
Half-way integrated is better than the patchwork quilt approach, but it still creates implicit silos of data, and introduces other hidden costs. Itâs like being half-way delicious.
The Whole Enchilada
Speaking of delicious, what happens when you *actually* integrate tasks, wiki, chat, releases, documents, source code, support, and continuous delivery If you could get all of these chunks of functionality in a single system, how would it affect your experience and productivity
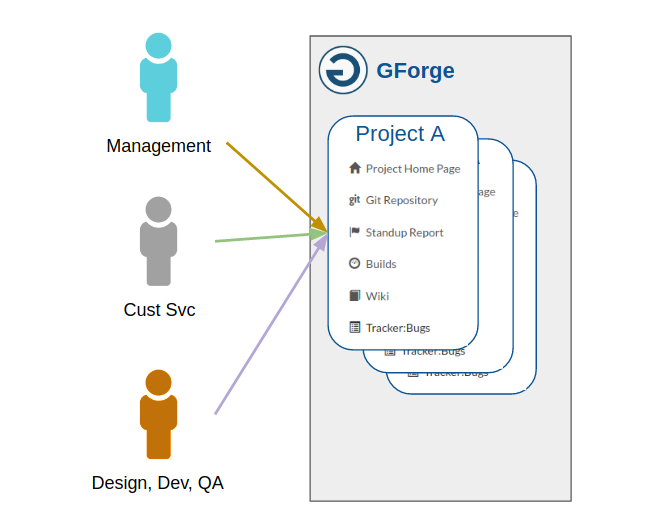
There are some big benefits:
- A seamless experience for managers, development staff, creatives, support and even customers to get involved in.
- A single source of truth for whatâs important, whatâs done, and whatâs next.
- One place for your institutional knowledge to live on. On-boarding becomes easy. Hard-won company wisdom doesnât disappear when someone leaves or changes roles.
- One search box that is deeply connected to all of your projects, source code, documents, information, tasks and discussions. Find a specific key word or error code no matter where itâs hiding.
There are lots of situations where best-of-breed thinking makes sense. In areas where a specific tool improves your productivity, saves money, or just makes work more fun, it can be worth it. If the need youâre filling isnât central to your business, then itâs not a huge risk to try (and maybe abandon) something new. But thatâs not what weâre talking about here.
The way your team organizes and works together is possibly the most important and valuable part of your entire business. Trying to run things using a patchwork quilt of point solutions might seem cool at first, but itâs probably not where you want your team spending their time.
Thatâs why we built GForge. Because we do what you do every day, and we think it should be easier.
Come try GForge Next, and let us know what you think.
Note: My editor wanted me to include email as part of this discussion, but it added way too much to the article. GForge does some great things with email, and I will publish something soon to show how and why.
The Same Old, Brand-New Argument: All-In-One or Best-Of-Breed?
Introduction
For at least the past twenty years, IT folks have been faced with the same basic problem when choosing whether and which products to adopt. The term âBest of Breedâ is commonly used to talk about products that offer high quality in a narrow set of features. âAll in Oneâ products, on the other hand, combine features that may cross business process or technical boundaries.
Different vendors have very different views on whether customers need a bunch of features integrated in a single product, or whether they would rather manage a set for more focused products that they (or someone else) can stitch together.
Whatâs the right way to go The answer is, of course, âit dependsâ â and while this may be accurate, itâs not very helpful without some practical criteria to apply.
The Trade-Offs
Learn To Let Go
First things first â as a customer, buying someone elseâs product means buying into their approach, their decisions, and their limitations. Youâre almost certainly not going to get *exactly* what you want. Then again, you wonât be building and maintaining your own code, spending money on adding features, and your development staff can be off chasing your *real* business goals.
Look at the Big Picture
Another big trade-off involves the *rest* of your business technology. How does your current need fit in with the rest of your business systems If you can cover more business requirements with one product, it means fewer integration points. If your requirements are very complex or specific, it might be worth the extra dependency to go after a best-of-breed tool in a given area.
Watch the Uptime
Lastly, consider outages and support. Itâs inevitable that youâll depend on your vendor(s) to come through for you when something goes wrong. Make sure you have a well-defined level of service with each vendor.
Outages can and will occur, and they affect your business continuity. Having a set of smaller, independent services from different vendors might seem like a good hedge against downtime, but in reality more moving parts *always* means a higher chance of failure. If four out of five systems are up, it doesnât mean you have 80% functionality â interdependency usually drives that number down pretty quickly as you add components.
Whatâs Right for You
With those trade-offs in mind, letâs go through a few questions that you can apply to your own situation, to help identify where you might find the most value:
1. How Big (Small) Is Your Scope
If your needs are pretty narrow (e.g., file storage, web analytics, payment processing), then itâs likely to be well-covered by a best-in-breed solution. If you need lots of features, or a lot of complexity within them (think workflow, document management, billing or accounting), then an integrated option will offer less difficulty to get up and running, even if it has some limitations you donât love.
2. How Much DIY Can You Handle
This one is pretty simple â the more pieces you add to your quilt, the more stitching youâll need to do. For example, youâll need to keep your list of customers updated between CRM and project management, or maybe get build status in your work chat.
Nowadays, itâs very typical for applications to offer an API right out of the box. Itâs also pretty common to have some integrations baked into tools â fill in a field or two, check the âEnabledâ box and itâs connected. But the ease of initial adoption can misrepresent the ongoing costs to keep things the way you want them. Here are some examples:
- Documented APIs are typically stable and reliable, but your custom integration with an API can become fragile over time, as your needs become more complex.
- Built-in integrations provided between vendors (especially âweb hookâ type integrations) are always vulnerable to compatibility issues between the vendors, as they add (and retire) features over time.
- Troubleshooting problems between multiple vendors is not for the faint-of-heart â you will often find yourself stuck in the middle, trying to prove that you have a problem they can solve.
If youâre a completely bootstrapped startup, where you have more time than money, it might make sense to invest that time into getting the tools you want tied together. As your organization grows, however, the balance between time and money often changes, and youâll need to re-evaluate some of those early decisions.
3. Who Are You Getting Involved With
Regardless of which way you go, youâll want to know some things about your vendor(s) before you sign on. Here are a few starters:
- First and foremost, are they going to disappear one random evening, with all your data
- How long have they been around
- How do they deal with customers during the sales cycle The support cycle
- Do they solicit/accept/ignore requests from their customer base Are they responsive to requests
- What levels of support (free or paid) are available Do they promise a specific level of service
- Do you know anyone else who is a customer What do they think
Depending on your size and level of formality, these questions may become much more important. Newer, smaller, bootstrapped companies may care a lot more about what they can get now, and less about whoâs answering the phone at 3AM. Organizations that have to answer to customers, boards of directors, investors or regulatory authorities might have an entirely different view. Uptime becomes much more important once you have paying customers, and people relying on your services.
4. What Will You Need Next Year In Three Years
If youâre a new company, patronizing another new company can seem like a great idea. Finding a focused vendor to partner and grow with can be a great fringe benefit â unless they go out of business or pivot away from what you need. Regardless of how good a relationship is at the beginning, itâs important to keep in mind how youâll get out if and when itâs time to move on.
Some services are easier to change than others, like payment processing or CDN â you can even use two vendors concurrently and make a soft switchover. For other tools, like bug tracking, CRM, or internal tooling (e.g., database, message queue, web platform), changing vendors can take time, attention and planning away from your more strategic goals. All of those distractions cost opportunities, sales, and revenue.
But thatâs not even the worst-case scenario. Instead, many teams will continue using tools that donât support them strategically, struggling along with more and more string and duct tape around a core that is no longer suited to them. This is a quiet, passive killer of your teamâs momentum and ability to innovate â especially if certain tools or systems become off-limits for discussions about improvement.
In general, I try to buy software and services the way that parents buy clothes for their kids. Sure, theyâre a little too big at first, but if you choose wisely, youâll find something you can grow into. Maybe even something you never outgrow.
If youâre looking for a task/code/team collaboration tool that youâll never outgrow, come check out GForge Next: https://next.gforge.com
HackISU: Intern Job Description
A quick run-down of the skills we’re looking for, and how we’ll put you to use.
Come and join a world-class company that supports thousands of project teams around the world. We’re looking for folks to fill one or both of two categories:
- First, customer service handling technical issues with customers – sysadmin stuff, configuration, tracking down log entries, etc.
- Second, help with building new features and testing GForge Next.
What weâre looking for:
- Work from home 12-20 hours per week, Monday through Friday. Specific start and end dates are very flexible.
- Weâre pretty flexible on schedule, as long as the results are right.
- For support duties: A moderate amount of knowledge in Linux/Web systems administration. Stuff like:
- Linux basics (ps, grep/find, sed/awk, top, iostat, etc.)
- Package mgmt (e.g., yum, apt-get, rpm, etc.)
- Scripting (bash, php)
- Apache httpd setup and config (conf files, modules, etc)
- Version control tools like CVS, SVN, Git.
- Bonus points for SQL and Postgres!
- For GForge Next development duties:
- Programming experience in PHP (or Python)
- SQL basics (bonus points for Postgres)
- Familiarity with HTML5 and CSS
- Some Javascript programming experience
- Extra bonus points for Angular 1.x experience.
- Great customer service attitude. Especially when they might have done it to themselves.
- Last and most important: willingness to learn a lot of cool stuff, and share what you know every day.
Responsibilities of the Job:
- Make customers really happy by fixing their problems.
- Research issues that donât have an easy answer.
- Willingness to dig into code to possibly give a better bug report to our engineering team. Maybe even dig in and fix the bug yourself.
- Work from wherever you like, but be productive and respond quickly during working hours.
- Lean on other GForge staff and share knowledge whenever possible.
- Stay in the loop â email is a given. We also camp out together in chat all day and have an informal daily standup, usually on Google Hangouts.
- Document solutions that can be re-used.
- Depending on how busy things are, we may even ask you to help test out new features and bug fixtures.
Intro to the GForgeNext API
GForgeNext is the newest incarnation of our long-lived project collaboration tool. It ties together all of the most important features that teams need to deliver big things – like task tracking, team chat and integrated source control. And in the next several months, we’ll add a lot more.
Next employs a Single Page Application (SPA) front end, and relies on our public REST API for all of its functionality. Everyone can now build great tools and integration points with GForge using the same REST API that we do.
On that topic, then, let’s explore the API and build an example or two.
REST Basics
There are plenty of good, detailed tutorials about REST. Here are the basics you need to get started with ours:
- REST deals in resources. In our case, things like users and projects.
- REST uses the HTTP verbs you already know to get things done. GET, POST, PUT and DELETE are the most common.
- REST also uses the same HTTP response codes that web pages use. 404 That record doesn’t exist. 400 You submitted something invalid. 500 You broke it.
- REST uses the normal query string and request body that HTML pages use.
- Data is typically exchanged (submitted and returned) in JSON format, which is easy to handle on most platforms.
- Our REST API also accepts regular FORM POST format, so it can be called even from static HTML pages or libcurl.
- All of the resources, methods and parameters for the API are documented in our API Docs.
Logging In
GForge has very deep and flexible access controls, and the data you receive from the API will usually depend on the user requesting it. You can submit a separate user ID and password with each request, or get a session ID (from the /usersession endpoint).
Using curl:
[code language=”bash”]
curl -X POST https://USERNAME:PASSWORD@next.gforge.com/api/usersession
[/code]
Results in:
[code language=”javascript”]
&amp;amp;amp;lt;pre&amp;amp;amp;gt;{
"SessionHash":"e3403h9ldbssr2…o781jne2"
}
[/code]
The POST verb is used to create data on the server – in this case, a new session ID is created if the user and password match up. You can then use the session ID in place of the password for further requests. In a browser, the session ID will also be set in a cookie just like visiting the login page on a web site.
To “log out” and remove this session:
[code language=”bash”]
curl -X DELETE https://USERNAME:SESSION@next.gforge.com/api/usersession/SESSION
[/code]
Result:
[code language=”javascript”]
{"result":"success"}
[/code]
Note that you have to include the session ID for both the authentication and to specify which session to delete.
Get Some Data
Now that we have an authenticated user, we can use it to get data from the API. How about the user profile for a friend
Request:
[code language=”bash”]
curl https://myuser:e3403…jne2@next.gforge.com/api/user/my_friend
[/code]
Result:
[code language=”javascript”]
{"id":99999,"unixName":"my_friend","password":null,"firstName":"My","lastName":"Friend",
"email":"my_friend@email.tld","status":1,"externalId":null,"isGroup":"N",
"ccode":"US","language":"en ",
"img_url":"/images/custom_avatars/99999.jpg",
"details_url":"/api/user/my_friend/details","api_url":"/api/user/my_friend"}
[/code]
What’s Next
Read the API docs, and see what you can get under the /api/user and /api/project endpoints. There are a whole bunch of sub-entities within each one. Then maybe move on to /api/tracker or even /api/trackeritem to see tasks.
For the especially brave, try /api/poll…
Got questions Comments Bugs Leave a comment, or find me on Twitter @mtutty.
GForge Next – The API
A couple of weeks ago, Tony shared some screen shots of GForge Next, and talked about how we’re designing it to Get Out of Your Way. Today, I’d like to talk about the other end of GForge Next – the API side.
We’ve Always Had An API
It’s true – the current GForge has an API, and it has for over ten years. But it’s……not awesome.
If you have ever worked with SOAP services, then you know they can be overly complex, verbose and yet inscrutable. Not to mention it can be fragile, especially between different platforms (I’m looking at you, Java/Axis/Axis2/XFire).
But the real flaw in our SOAP API is that is was bolted on to the existing code. There’s quite a bit of logic shared between the GForge UI and the SOAP API, but also some duplicate code, so the API won’t always act the same way as the good old web UI. As we continue to fix bugs and add features, it continues to be an extra effort to maintain these separate code modules and keep them working the same way.
Now With 100% More REST
Like everything else with GForge, we are our own worst critics, and our own first users. So it was easy for us to decide that to be useful, the API had to be an integral part of the system. The entire GForge Next UI runs against the API. Logging in API call. Getting your list of assigned tasks API call. When we use GForge Next UI to accomplish tasks, we’re also automatically making sure that integration via the API will work for all of those use cases.
For wire protocol, we chose REST (like pretty much everyone else these days). JSON + HTTP (GET, POST, PUT, DELETE) is a pretty simple, readable and capable combination, and it aligns nicely with the other parts of our technology stack (like AngularJS and Bootstrap).
The API is even self-documenting thanks to code-comment blocks in the underlying services and our /apidoc endpoint. The API docs include all the entities, methods, parameters and even example input and output. As we continue to add and change the API , the docs are automatically up to date.

For the most part, we submit data to the API using the same JS objects we receive from it. That way, we can take an object from a list of values, assign it as a property on another object and submit it. Super-simple on the client side, and pretty easy on the server as well. But for external integration, it’s not so great. Requiring callers to fetch a bunch of lists and sub-objects in order to properly craft a request makes the API less usable and more prone to invalid requests. So, for most requests, we will accept any of the following values for sub-objects (like a project, a status, the user, etc.):
- The “official” JS object for that type (retrieved from the API)
- The ID or alias for the object, as a number or string value. For example, ID 2000 or the short name mtutty for a user.
- A JS object with an ID property, with the same value as the above bullet.
In general, the API back-end will work pretty hard to figure out what value you’re trying to use, and go find it based on the ID or key value submitted. We also support vanilla FORM POST semantics, so that regular HTML forms, curl and wget requests are easy to do.
Complex Can Still Be Simple
So it’s pretty easy to create a basic CRUD API for a set of related tables. The current GForge Next database has about 137 tables, which is a bit more complicated. Add to that the fact that most realistic use cases (including our own UI views) are going to need multiple types of data, and using the API just went back to difficult and confusing. Well, maybe not.
Largely for our own needs, we started adding related data as optional for many API calls. By adding “rel=xyz” to a GET request, you can ask the GForge Next API for additional data that is related to the entity (or entities) you’re requesting. So for example, GET /api/user/mtutty/details rel=projects,activitylog includes the most-used projects and most-recent activity records for me. That’s all the data needed for the user profile view, in one call.
Don’t need all that extra stuff Don’t include the rel, and you can get the payload down from 3.6K to 963 bytes.
How About Some Examples
Here are a couple of ways we’re already using the API (outside of our own UI) to keep project data and knowledge moving, even when things are happening outside of GForge.
Build and Deployment Activity – We use Jenkins for CI/CD (and deploy GForge Next several times every day). Whenever builds start or fail, or whenever a deployments starts or ends, we use the REST API to log an activity record. This is visible in the Project Home page activity view and in the project chat room (which is where we see it most of the time). Now as we’re working on tasks, we can see not only what tasks other people are working on, and their funny cat pictures, we can also see our build kicking off, and code going live, in real time.

Customer Feedback – First Dozen users will notice the green “Feedback” tab on every page in Next. That tab submits data to a separate Tracker called, well, “Customer Feedback”, using the API. Technically it’s part of our site but we have made a conscious effort to keep it separate from the AngularJS application that contains the rest of GForge Next. The Tracker template will be available in GForge Next, and eventually we’ll make the widget available too, so customers can collect feedback from users directly into their GForge Next project.

Where To Go From Here
While we are excited for the new REST API in GForgeNEXT what really excites us is the creative ways developers will use the API. Because the API is new and will continue to develop, we really hope you consider signing up for early access to GForgeNEXT. Those requesting early access will can expect the beta to begin officially over the next couple of weeks which will include immediate access to the API.